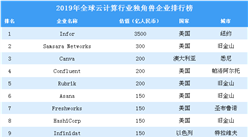
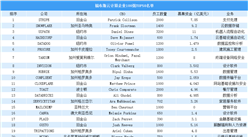
整合要来了吗?
从上图可看出,这张图已经变得越来越拥挤,那么一个显然的问题来了:行业是否濒临大规模整合的边缘了呢?
似乎还没有。至少目前如此。
首先VC仍然继续乐于给新老公司提供资金扶持。2017年的第一季度成长阶段的大数据初创企业拿到了不少的可观融资,其中包括:Looker(8100万美元D轮),InsideSales(5000万美元F轮),DataRobot(5400万美元C轮),Confluent(5000万美元C轮),Collibra(5000万美元C轮),Uptake(4000万美元C轮),WorkFusion(35M00万美元D轮)andMapD(3500万美元B轮)等。去年12月DataBricks也拿到了6000万美元的C轮。
2016年,大数据初创企业的总融资达到了148亿美元,占到了全球技术风险投资的10%。
其次,自去年的大数据版图推出以来,本领域的并购活动一直在稳步推进,但不是特别显著,其中部分原因也许是未上市公司的估值仍然高企。入选2016大数据版图的公司当中共有41家被收购(完整清单参见附注),这个节奏跟上一年是一致的。
另一方面,2017年刚开始就发生了一些大型的并购事件,其中包括Mobileye(被英特尔以153亿美元收购),AppDynamics(被思科以37亿美元收购),以及NimbleStorage(被HPE以12亿美元收购)。
去年还有一个显著的现象,那就是大型技术公司纷纷收购AI初创企业,尤其是那些解决水平问题、有着很好团队的AI初创企业。其中包括Turi(苹果)、MagicPony(Twitter)、VivLabs(三星)、MetaMind(Salesforce)、GeometricIntelligence(Uber)、API.ai(Google)以及Wise.io(GE)。当然,这种现象未必能持续太久,因为对AI的需求太旺盛了,人才实在是不够用了。
第三,一些较大的大数据初创企业羽翼渐丰,正在成为独立的上市公司。Snap无疑引领了技术公司IPO的复兴,但是目前为止是大数据公司借了这股东风。
2016年只有Talend一家大数据公司上市,但2017年大数据公司已经呈现出爆发之势。其中Mulesoft和Alteryx已经上市并且表现不错,而Cloudera也即将上市,其最新估值(41亿美元)与收入(2.61亿美元)之间的差异将延至“独角兽”估值现象的成色。另外,MapR以及定位智能公司Yext也已经在排队等待了。
下一个会是谁呢?也许是Palantir这个超级独角兽。这家多年以来保持神秘的公司已经公开表达了上市的兴趣。其最新估值达到了200亿美元,如果上市的话必将引起轰动。
云大战
虽然大规模并购尚未出现,但业界的另一股趋势值得注意,这就是“功能性整合”,这种现象在云端尤其显著。一些关键的玩家正在通过自研产品和开源计算引擎的实现逐步构建“大数据+AI”的基础构件,面向众多客户群提供其所期盼的“一站式”的服务。
AWS在产品发布的速度和幅度方面继续给人留下深刻印象。目前AWS几乎提供了大数据和AI方面的所有服务,包括分析框架、实时分析、数据库(NoSQL、图谱等)、商业智能以及日益丰富的AI能力,尤其是深度学习方面的能力。按照这种速度发展下去,AWS产品几乎就要把大数据版图的所有的基础设施和分析细分领域都占据了。
加入云大战稍晚的Google一直在积极开发广泛的大数据产品(BigQuery、DataFlow、Dataproc、Datalab以及Dataprep等),并且把AI视为跨越式发展的杀手锏。在AI方面Google去年做了很多事情,包括推出了新的翻译引擎,聘请了李飞飞和李佳领导新成立的CloudAIandMachineLearning部门,推出了视频识别的机器学习API,并且收购了数据科学家社区Kaggle。
其他大型的IT供应商,比如微软、IBM、SAP、Oracle以及Salesforce等也在努力推出大数据产品(包括云端和本地)。除了技术自研和进行收购以外,这些玩家还越来越重视通过合作来打造生态链,其合作的重点是手上有数据的公司以及有“头脑(AI)”的公司。IBM与Salesforce的合作以及SAP与Google的合作就是值得注意的案例。
用企业IT的行业标准来看,云供应商还比较小,但是其不断膨胀的野心(其中包括从企业栈底层的IaaS向应用发展的企图)与企业数据逐渐向云端迁移的趋势结合,将打开庞大的企业技术市场大门,与传统IT供应商展开激战,而大数据和AI将是核心战场。
2017数据生态体系概览
基础设施
去年的许多趋势今年仍将延续,比如流处理技术,这方面Spark目前是主宰,不过像Flink这样的有趣竞争者正在出现。此外,还有以下一些趋势:
SQL正式回归
在给NoSQL当了10年副手之后,曾经的霸主SQL数据库正式吹响了回归的号角。Google最近发布了Spanner数据库的云端版。Spanner和CockroachDB(Spanner的开源版)都提供了可行的、强一致性的、可伸缩的SQL数据库。Amaozn推出了Athena,跟Snowflake等产品类似,这是一款SQL数据引擎,可直接查询S3下的数据。GoogleBigQuery、SparkSQL以及Presto等在企业逐渐获得采用——这些都是SQL产品。
数据可视化
与公有云采用相关的一个有趣的趋势是数据可视化。旧的ETL处理需要转移大量的数据(而且往往要建立冗余数据集)并且建立数据仓库,而数据可视化可以在数据保持不动的情况对其进行分析,提高了速度和敏捷性。许多下一代的分析供应商现在都可以同时提供数据可视化和数据准备服务,并让客户可访问存储在云端的数据。
数据治理与安全
随着大数据在企业侧走向成熟,以及数据的多样性和体量的不断发展,像数据治理这样的主题也变得日益重要。许多公司已经选择了“数据湖”作为把所有数据收集起来的手段。但除非你知道里面有什么东西,并且能够访问到合适的数据进行分析,否则的话数据湖再大也没有意义。但是想让用户方便地找到想要的东西同时管理好权限并不容易。除了数据湖以外,治理的另一个集中的主题是以安全的、可审计的方式为任何人提供对可靠数据的便捷访问。Informatica、Collibra、Alation等大小供应商提供了数据目录、参考数据管理、数据字典以及数据帮助台等服务。
 如发现本站文章存在版权问题,烦请联系editor@askci.com我们将及时沟通与处理。
如发现本站文章存在版权问题,烦请联系editor@askci.com我们将及时沟通与处理。


 中商产业研究院:《2020年中国加氢站行业市场前景及投资研究报告》发布
中商产业研究院:《2020年中国加氢站行业市场前景及投资研究报告》发布
 锤子科技CEO罗永浩跨界电商直播 一文看懂我国电商直播发展如何?
锤子科技CEO罗永浩跨界电商直播 一文看懂我国电商直播发展如何?
 中商产业研究院:《2020年中国MCN行业市场前景及投资研究报告》发布
中商产业研究院:《2020年中国MCN行业市场前景及投资研究报告》发布
 2020年1-2月全国汽油产量为2044万吨 同比下降13.9%
2020年1-2月全国发电量同比下降8.2%
2020年1-2月全国集成电路产量为296.3亿块 同比增长8.5%
2020年受疫情影响较大的行业分析系列之三——旅游行业篇(图)
2020年1-2月全国光缆产量统计数据分析
2020年1-2月全国发动机产量同比下降38.8%(图)
2020年1-2月全国十种有色金属产量为935.4万吨 同比增长2.2%
2020年1-2月全国汽油产量为2044万吨 同比下降13.9%
2020年1-2月全国发电量同比下降8.2%
2020年1-2月全国集成电路产量为296.3亿块 同比增长8.5%
2020年受疫情影响较大的行业分析系列之三——旅游行业篇(图)
2020年1-2月全国光缆产量统计数据分析
2020年1-2月全国发动机产量同比下降38.8%(图)
2020年1-2月全国十种有色金属产量为935.4万吨 同比增长2.2%