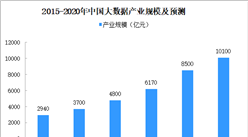
作为该系列的开篇文章,本期我们将从宏观的角度带你观察大数据行业的整体生态结构,对大数据采集、数据的分布式存储与处理,以及在此基础之上的数据分析、可视化和在众多行业中的应用进行概述。其后的每篇文章我们都会挑选大约5个行业的数十家典型公司进行详细介绍,并会对其中一个重点行业进行逻辑的梳理与详细案例的剖析。那么首先我们就来说说大数据技术是如何产生的?

第一大数据的技术基础
早在1980年,着名未来学家托夫勒在其所着的《第三次浪潮》中就热情地将“大数据”称颂为“第三次浪潮的华彩乐章”,这标志着人们首次对海量数据所能够产生的价值有了初步的了解。
但由于连接方式的局限,长期以来人们对于数据的应用大多以企业内部的商业智能为主,随着互联网、移动互联网的普及,企业终于能够直接与用户产生链接并获得大量的用户行为与消费等数据,大数据产业应用的轮廓才渐渐清晰。
2000年初Google为了实现对大量网页的信息抓取、存储,并完成索引的建立及排序功能,同时又希望降低硬件采购成本而逐渐摸索出了利用普通物理机实现的分布式存储、计算体系。这一技术以MapReduce及GFS而为人所熟知,借此大数据得以分布存储在多个数据库中,并进行大规模并发处理,解决了以往单一计算机存储能力不够,计算时间过长而不具备实用性的问题。
依据2003年底Google所发布的论文,前雅虎工程师开发出了类似的分布式存储计算技术Hadoop,随后围绕Hadoop产生了庞大的生态体系,逐渐使大数据基础架构日臻完善。
Hadoop功能包括从数据采集、存储、分析、转运、再到页面展示,完整涵盖了整个流程。例如HDFS实现了数据的分布式存储,HBase负责实现数据库的功能,Flume执行对数据的收集,Sqoop能够对数据进行转移、治理,MapReduce可以通过算法实现分布式计算,Hive则做数据仓库,Pig做数据流处理,Zookeeper实现了各节点间的反馈收集与负载平衡服务,Ambari能够让管理员了解架构整体的工作运行情况。
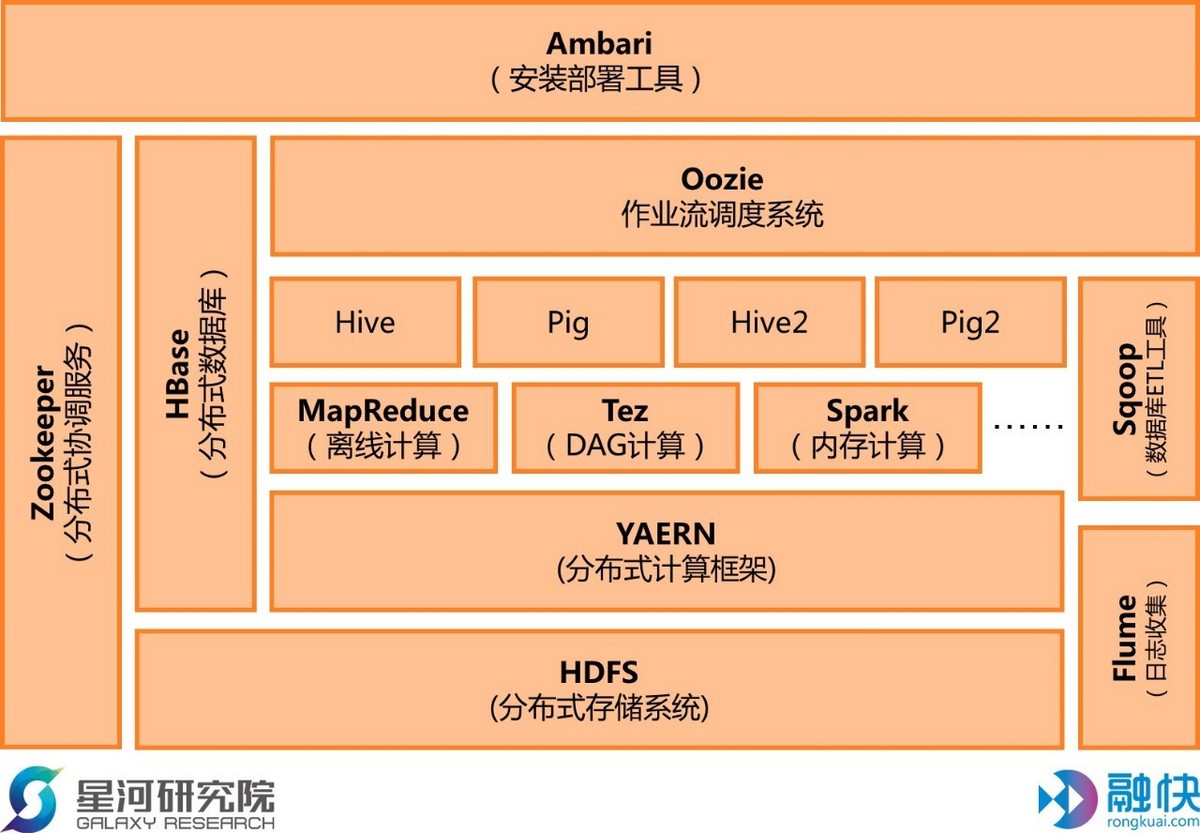
Hadoop生态技术架构
而随着技术的发展,一些适应独特应用场景的数据库、计算处理等软件也越发丰富,例如非结构化数据库MongoDB就因为其较为强大的条件查询功能以及灵活的数据结构获得了广泛的应用;Spark则将Hadoop中的存储介质替换为闪存,而获得了百倍处理速度的增长,DatabricksCloud就是这一架构下的产品化服务。
除此之外大数据生态中还存在着很多的技术发展路径,其中MPP技术主要还是以关系型数据库为主和Hadoop技术目标类似,都为了将数据切分、独立计算后再汇总。相对于SQLonHadoop,MPP具有数据优化程度高、计算速度快,擅长被用于进行交叉分析等优点,适合企业进行数据分析使用,但其扩展性相对Hadoop来说较弱,一般在10个节点以上便丧失了计算优势,并且由于非开源架构导致其对特定硬件依赖程度较高。
采用MPP存储模式的代表性公司有Teradata,能够通过进行企业数据分析帮助员工减轻大数据处理的精力消耗与费用成本,使企业能够更加专注于业务运营。在传统数据库公司与意图进入数据库市场的企业服务公司(例如SAP)掀起的收购热潮中,Teradata是目前市场仅存的几家大型独立数据分析公司之一。
 如发现本站文章存在版权问题,烦请联系editor@askci.com我们将及时沟通与处理。
如发现本站文章存在版权问题,烦请联系editor@askci.com我们将及时沟通与处理。


 “新基建”赋能轨道交通 城际高速铁路和城际轨道交通产业链全景图分析(图)
“新基建”赋能轨道交通 城际高速铁路和城际轨道交通产业链全景图分析(图)
 中商产业研究院:《2020年中国加氢站行业市场前景及投资研究报告》发布
中商产业研究院:《2020年中国加氢站行业市场前景及投资研究报告》发布
 锤子科技CEO罗永浩跨界电商直播 一文看懂我国电商直播发展如何?
锤子科技CEO罗永浩跨界电商直播 一文看懂我国电商直播发展如何?
 中商产业研究院:《2020年中国MCN行业市场前景及投资研究报告》发布
2020年1-2月全国汽油产量为2044万吨 同比下降13.9%
2020年1-2月全国发电量同比下降8.2%
2020年1-2月全国集成电路产量为296.3亿块 同比增长8.5%
2020年受疫情影响较大的行业分析系列之三——旅游行业篇(图)
2020年1-2月全国光缆产量统计数据分析
2020年1-2月全国发动机产量同比下降38.8%(图)
中商产业研究院:《2020年中国MCN行业市场前景及投资研究报告》发布
2020年1-2月全国汽油产量为2044万吨 同比下降13.9%
2020年1-2月全国发电量同比下降8.2%
2020年1-2月全国集成电路产量为296.3亿块 同比增长8.5%
2020年受疫情影响较大的行业分析系列之三——旅游行业篇(图)
2020年1-2月全国光缆产量统计数据分析
2020年1-2月全国发动机产量同比下降38.8%(图)